
Understanding Volatile: A CUDA Prefix Sum Story
While working on an assignment for a parallel programming class, one of the tasks was to fix a buggy renderer and make it faster.
The project provided a scan implementation for students to use, which calculates the prefix sums of an array. I was curious why they provided an implementation instead of asking us to implement our own, since prefix sums didn’t look like a complicated task.
I'd taught the parallel scan algorithm as a teaching assistant for two, going on three semesters (much love to our mascot Clarabelle the Parallel Cow), and wondered how difficult it would be to translate this theory into CUDA code.
So, venturing outside the requirements of the project, I implemented a CUDA-optimized prefix sum algorithm using shared memory for warp-level parallelism. At first, I found out that my version didn’t perform as well as the provided version.
To get my version to meet and later exceed the provided scan implementation, I did some research from sources [1][2], as well as reverse engineering the provided render_soln to understand the provided scan implementation.
A confession from 2025 Jess: Yes, I decompiled
render_solnto figure out why it outperformed my implementation, which led to the optimization that eventually allowed me to beat it. Now that I have my degree, it's okay to disclose. :^)The reverse engineering process was incredibly educational and helped me understand GPU optimization at a level I wouldn't have otherwise achieved. To the course staff that's retroactively reading this, your beautifully optimized code taught me more about GPU programming than any lecture could have. Thank you.
Future students, ask your instructors first! Some courses permit reverse engineering provided code as learning; others call it academic misconduct.
This exploration led to several key learning moments for me, as it was my first time:
- Understanding a use case for
volatile - Reading GPU instructions, in which
cuobjdumpandcu++filtwere helpful tools [3]
so the diversion was worthwhile even if not required by my class.
Prefix Sum for 32-Sized Block
In short, I was trying to implement the algorithm described in Algorithmica, where the array is split into blocks of size 32, the prefix sum of each block is calculated, and the results of these blocks are later combined [1].
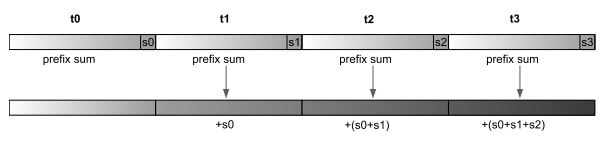
I was implementing the CUDA equivalent to Algorithmica's SIMD implementation, in which each 32-lane SIMD is equivalent to a 32-thread warp in CUDA, and each vector lane is equivalent to a thread in CUDA.
In this post, I will only discuss the process for calculating the prefix sum within a block, as combining the results of these blocks is a separate story.
Imagine you're standing in a line, with each person in line holding a number. Your task—as is the task of each person in the line—is to calculate the sum of the numbers from your position to the front of the line.
You can do it as follows:
Round 1: Ask the person in front of you for their number and add it to your number. Now you have the sum of the first two numbers.
Round 2: Ask the person two positions in front of you for their sum from round 1 and add it to your number. Now you have the sum of the first four numbers.
Round 3: Ask the person four positions in front of you for their sum from round 2 and add it to your number. Now you have the sum of the first eight numbers.
...
Round 5: Ask the person sixteen positions in front of you for their sum from round 4 and add it to your number. Now you have the sum of the first 32 numbers.
This is the general idea of the following CUDA code for calculating the prefix sum of an array of size 32, where each person in line is a CUDA thread, and
- the
ith person in line executesinclusivePrefixSumWARP(scratch + i, array[i])array[i]is the number held by theith personscratch[32 + i]gets populated with the sum of the firsti + 1numbers inarray
scratchis a2*32sized array where the first half is 0 and the last half holds the final result
__device__ __inline__ int inclusivePrefixSumWARP(
int * data,
int myvalue
) {
data[0] = 0;
data[32] = myvalue;
data[32] += data[32 - 1];
data[32] += data[32 - 2];
data[32] += data[32 - 4];
data[32] += data[32 - 8];
data[32] += data[32 - 16];
return data[32];
}
Below how each step would look if we adapt it for an array of size 8.
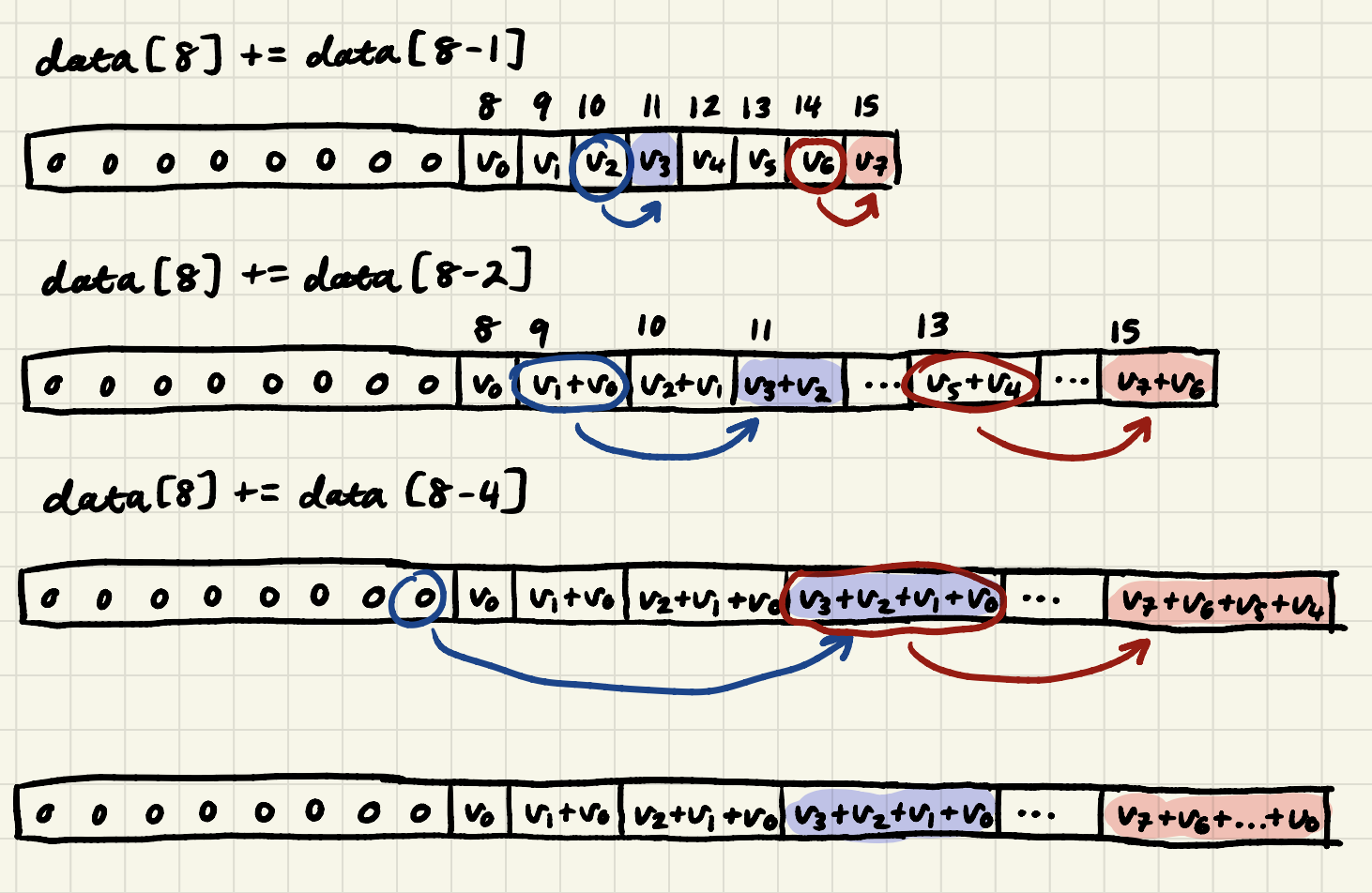
I recommend following the trace of thread 3 in blue, as well as thread 7 in red.
Clarification: All the threads execute each line at the same time, no synchronization needed. In other words, at the end of
data[0] = 0, threads 0 to 31 will have populatedscratch[0...31]with0. At the end ofdata[32] = myvalue, threads 0 to 31 will have populatedscratch[32...63]witharray[0...31], etc.This is one difference between pthreads and CUDA threads. For pthreads, synchronization is needed because 1) the OS starts them at different cycles, 2) some threads may be slower than others due to various reasons such as cache misses. For CUDA threads, there is hardware support to make sure all threads in the same warp are synchronized, even if there are cache misses.
As long as CUDA threads don't get on divergent branches, which happens when you have conditional
if...elsestatements,__sync_warp()is not needed.
I'm no longer in secondary school, so Wikipedia is a credible source.
Our Code is Wrong
Our code is missing something very crucial that gives us incorrect results.
__device__ __inline__ int inclusivePrefixSumWARP(
int * data,
int myvalue
) {
...
}
But when we mark data as volatile...
__device__ __inline__ int inclusivePrefixSumWARP_old(
volatile int * data,
int myvalue
) {
...
}
we get correct results!
Why? Without Volatile
Let's see what instructions get generated for the no-volatile version of our code.
mov.u32 %r89, 0;
st.shared.u32 [%r17], %r89; # data[0] = 0
ld.shared.u32 %r90, [%r17+124];
add.s32 %r91, %r90, %r88; # myvalue += data[32 - 1]
ld.shared.u32 %r92, [%r17+120];
add.s32 %r93, %r92, %r91; # myvalue += data[32 - 2]
ld.shared.u32 %r94, [%r17+112];
add.s32 %r95, %r94, %r93; # myvalue += data[32 - 4]
ld.shared.u32 %r96, [%r17+96];
add.s32 %r97, %r96, %r95; # myvalue += data[32 - 8]
ld.shared.u32 %r98, [%r17+64];
add.s32 %r25, %r98, %r97; # myvalue += data[32 - 16]
st.shared.u32 [%r17+128], %r25; # data[32] = myvalue
This is equivalent to
__device__ __inline__ int inclusivePrefixSumWARP(
int * data,
int myvalue
) {
data[0] = 0;
int tmp = myvalue; // tmp is a register the compiler picks
tmp += data[32 - 1];
tmp += data[32 - 2];
tmp += data[32 - 4];
tmp += data[32 - 8];
tmp += data[32 - 16];
data[32] = tmp;
return tmp;
}
Interesting! This is not quite what we wrote originally.
Compiler Optimizations
Our friend the compiler loves to make optimizations where it can. It sees our source code and asks, Woah there, why are we making so many accesses to data[32]?
__device__ __inline__ int inclusivePrefixSumWARP(
volatile int * data,
int myvalue
) {
data[0] = 0;
data[32] = myvalue;
data[32] += data[32 - 1];
data[32] += data[32 - 2];
data[32] += data[32 - 4];
data[32] += data[32 - 8];
data[32] += data[32 - 16];
return data[32];
}
Let me fix that for you. Look at how fewer accesses we make!
__device__ __inline__ int inclusivePrefixSumWARP(
int * data,
int myvalue
) {
data[0] = 0;
int tmp = myvalue; // tmp is a register the compiler picks
tmp += data[32 - 1];
tmp += data[32 - 2];
tmp += data[32 - 4];
tmp += data[32 - 8];
tmp += data[32 - 16];
data[32] = tmp;
return tmp;
}
Unfortunately, the compiler does not know that data is shared by multiple threads, nor that we intentionally did it our original way because we want to share information with those other threads.
To elaborate, suppose we are thread 3. All we know is that we have some kind of number myvalue = v3 and some shared array data. We know nothing about what other numbers are out there, only that we have the number v3.
To get information about what other numbers are out there, we have to look in our shared array data. We trust that other threads will put their numbers in data, and we will do our part in putting our numbers in data so that other threads can see.
For starters, our correct behavior would be to store v3 in scratch[32 + 3], so that other threads whose sum needs v3 can get v3. This is what the data[32] = myvalue statement of our original code does.
__device__ __inline__ int inclusivePrefixSumWARP(
volatile int * data,
int myvalue
) {
data[0] = 0;
data[32] = myvalue; // store myvalue in second half of scratch
data[32] += data[32 - 1];
data[32] += data[32 - 2];
data[32] += data[32 - 4];
data[32] += data[32 - 8];
data[32] += data[32 - 16];
return data[32];
}
Note that in the compiler-optimized code, we no longer initialize data[32] before we do the adding steps. In other words, the last half of scratch is garbage.
Next, note that when we do the adding steps, we don't store our intermediary sums in data[32]. Other threads cannot see our sums, nor can we see the sums of other threads. In other words, we're adding garbage to garbage. Sometimes, combining garbage with garbage gives you gold, but this is not one of those times :(
After Marking It Volatile
Marking data as volatile fixes the issue. In essence, the volatile keyword tells the compiler that data may change at any time, outside of the code it sees (i.e. the compiler should not assume that the current program is the only part of the system modifying data).
__device__ __inline__ int inclusivePrefixSumWARP(
volatile int * data,
int myvalue
) {
data[0] = 0;
data[32] = myvalue;
data[32] += data[32 - 1];
data[32] += data[32 - 2];
data[32] += data[32 - 4];
data[32] += data[32 - 8];
data[32] += data[32 - 16];
return data[32];
}
Since the compiler no longer makes this assumption about data, it refrains from optimizations and generates the following instructions:
mov.u32 %r89, 0;
st.volatile.shared.u32 [%r17], %r89; # data[0] = 0
st.volatile.shared.u32 [%r17+128], %r88; # data[32] = myvalue
ld.volatile.shared.u32 %r90, [%r17+128]; # %r90 = data[32] <-- redundant!
ld.volatile.shared.u32 %r91, [%r17+124]; # %r91 = data[32 - 1]
add.s32 %r92, %r90, %r91; # %r92 = data[32] + data[32 - 1]
st.volatile.shared.u32 [%r17+128], %r92; # data[WARP_SIZE] = %r92
ld.volatile.shared.u32 %r93, [%r17+128]; # %r93 = data[32] <-- redundant!
ld.volatile.shared.u32 %r94, [%r17+120]; # %r94 = data[32 - 2]
add.s32 %r95, %r93, %r94; # %r95 = data[32] + data[WARP_SIZE - 2]
st.volatile.shared.u32 [%r17+128], %r95; # data[32] = %r95
ld.volatile.shared.u32 %r96, [%r17+128]; # %r96 = data[32] <-- redundant!
ld.volatile.shared.u32 %r97, [%r17+112]; # %r97 = data[32 - 4]
add.s32 %r98, %r96, %r97; # %r98 = data[32] + data[WARP_SIZE - 4]
st.volatile.shared.u32 [%r17+128], %r98; # data[32] = %r98
ld.volatile.shared.u32 %r99, [%r17+128]; # %r99 = data[32] <-- redundant!
ld.volatile.shared.u32 %r100, [%r17+96]; ...
add.s32 %r101, %r99, %r100;
st.volatile.shared.u32 [%r17+128], %r101;
ld.volatile.shared.u32 %r102, [%r17+128];
ld.volatile.shared.u32 %r103, [%r17+64];
add.s32 %r104, %r102, %r103;
st.volatile.shared.u32 [%r17+128], %r104;
ld.volatile.shared.u32 %r25, [%r17+128];
Now we see that it's correct, as each thread writes their intermediary results to data as desired.
But we have potential for improvement. Now that the compiler knows data is volatile, it plays extra carefully. For every data[32] += thing statement, it does the following:
- Load the most recent value of
data[32]. Sincedataisvolatile,datacan change at any time outside of the visible code. - Calculate the sum of
thinganddata[32] - Store sum back into
data[32]
We see that the compiler has to load the most recent value of data[32] for every add step, and this contributes a lot of instructions.
Double the Lines = Less Instructions?
After we submitted the assignment, I found an improvement that would get my prefix sum to perform slightly better than the provided scan:
__device__ __inline__ int inclusivePrefixSumWARP(
volatile int * data,
int myvalue
) {
data[0] = 0;
data[WARP_SIZE] = myvalue;
myvalue += data[WARP_SIZE - 1];
data[WARP_SIZE] = myvalue;
myvalue += data[WARP_SIZE - 2];
data[WARP_SIZE] = myvalue;
myvalue += data[WARP_SIZE - 4];
data[WARP_SIZE] = myvalue;
myvalue += data[WARP_SIZE - 8];
data[WARP_SIZE] = myvalue;
myvalue += data[WARP_SIZE - 16];
return myvalue;
}
The instructions generated are
mov.u32 %r89, 0;
st.volatile.shared.u32 [%r17], %r89; # data[0] = 0
st.volatile.shared.u32 [%r17+128], %r88; # data[WARP_SIZE] = myvalue
ld.volatile.shared.u32 %r90, [%r17+124];
add.s32 %r91, %r90, %r88; # myvalue += data[WARP_SIZE - 1]
st.volatile.shared.u32 [%r17+128], %r91; # data[WARP_SIZE] = myvalue
ld.volatile.shared.u32 %r92, [%r17+120];
add.s32 %r93, %r92, %r91; # myvalue += data[WARP_SIZE - 2]
st.volatile.shared.u32 [%r17+128], %r93; # data[WARP_SIZE] = myvalue
ld.volatile.shared.u32 %r94, [%r17+112];
add.s32 %r95, %r94, %r93; ...
st.volatile.shared.u32 [%r17+128], %r95;
ld.volatile.shared.u32 %r96, [%r17+96];
add.s32 %r97, %r96, %r95;
st.volatile.shared.u32 [%r17+128], %r97;
ld.volatile.shared.u32 %r98, [%r17+64];
add.s32 %r25, %r98, %r97;
That's almost half as many instructions, even though our source code was longer! This is because
myvalueis non-volatile. For eachmyvalue += thingstatement, the compiler knows thatmyvalueis not volatile and thus does not have to load its most recent value for every add step.- We use
data[32] = thinginstead ofdata[32] += thing. The compiler does not need to know the previous value ofdata[32]because it will writethinginto it regardless, and thus this saves us from the load that would have happened for volatiledata.
In Short
A lot of findings surprised me. Before this, I'd heard the definition of volatile several times in books and in passing, but could not describe a use case for it. The improvement with storing intermediary results in myvalue was also surprising and interesting to me. In short, I'll be more careful with writing code the compiler can be helpful to a fault.
