
Deep Learning 1/N: First Thoughts on Deep Learning
I was pretty removed from the AI hype for my first three years of college. I had a little experience training neural networks, but the experience hadn't stuck with me nearly as much as other interest areas did, and so I didn't pursue AI.
In my final year, I finally decided to explore the deep learning and machine learning course offerings, partly because I came across some applications that had me like, "Oh, this is pretty useful!" To name a few that gave me this "oh!" reaction: app intents, AI-assisted coding environments, voice reconstruction. I look forward to seeing how this area progresses!
The first thing that jumps out to me--not directed at the teaching quality, but the nature of the field--is the lack of satisfying explanations for why things work. Lectures and weekend quizzes are dense in theory and math, not many pithy proverbs I can sprinkle onto my code to make it work.
And even as I try things, it feels like a, "It works now but I don't know why." There's no line I can cite, no sequence of instructions I can point to to explain behaviors.
So I'll jot down some notes as someone figuring out this area. For later posts, I have some newcomer's thoughts on how the curriculum could be redesigned and what I might be interested in seeing more of. I may turn this into a collection of posts if I have more thoughts.
Why does model A perform better than model B?
After sinking lots of time and trial-by-error to get my model to meet the high cutoff of 11-785's HW1P2 and briefly reaching #5 on the Kaggle scoreboard, I propose that
tuning learning rate >> architecture?
The tweaks I made to architecture, it's debatable how much they improved performance. Every little architectural decision may matter when networks are small, but for larger networks, I really think that the impact of architectural decisions gets dwarfed by training.
That is, if model A performs better than model B,
- it won't be because model A's layer 4 had 2048 neurons, while model B's layer 4 had some other amount of neurons
- it won't be because model A padded data some way, while model B padded data some other way
- and so on, and so forth.
I saw more direct results from steering the training with learning rate. My two cents is that if the model has enough neurons, then its architecture is good enough! The rest is training, namely
- how long it was trained
- ☆ how learning rate was tuned as it trained
So, how do we tune learning rate?
Learning Rates 101
We want our model's loss to converge to a minima, right?
My professionally unrigorous explanation is that there's a blind man wandering around the loss hyperplane, and we're guiding him into the deepest hole.
Exercise 1: Jumping into Holes
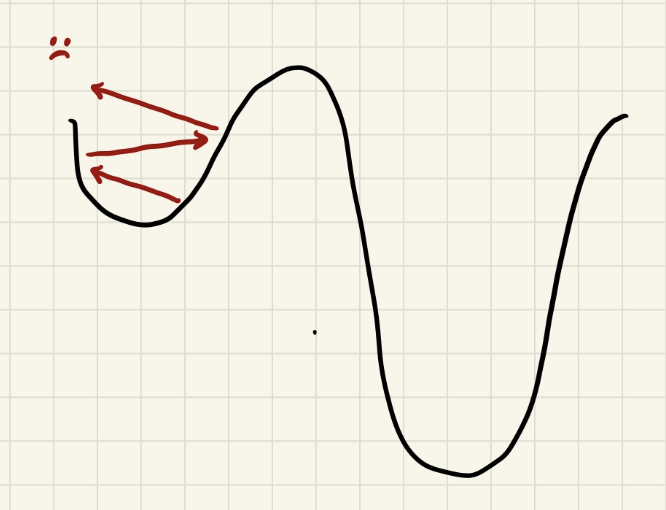
When learning rate is too high, the blind man can't fall into the hole. It's like wall-jumping you see in platformer games; he kind of wall-jumps against the hole and can't lower himself down.
 I drew the loss function in 2D, but it's usually some N-dimensional function that's hard to visualize.
I drew the loss function in 2D, but it's usually some N-dimensional function that's hard to visualize.
We must decrease learning rate to help him fall into the hole:
Exercise 2: Bouncing Out of Holes
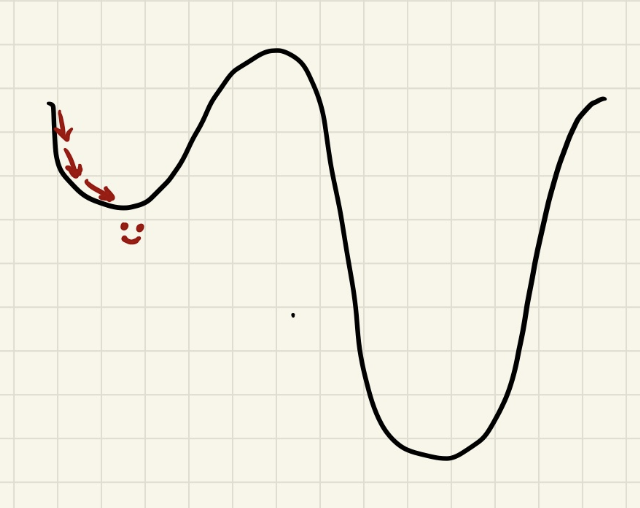
The blind man fell into the hole, but it might not be the deepest hole.
This is where we clone the model and start a new run, so that if we guess wrong and leave our blind man holeless and hopeless, we have a savepoint to fall back on. This also lets us make bigger changes to the config without throwing away our good results.
Here's how I named my model and a few of its multiverse selves. Note this is just "a few," ahah...
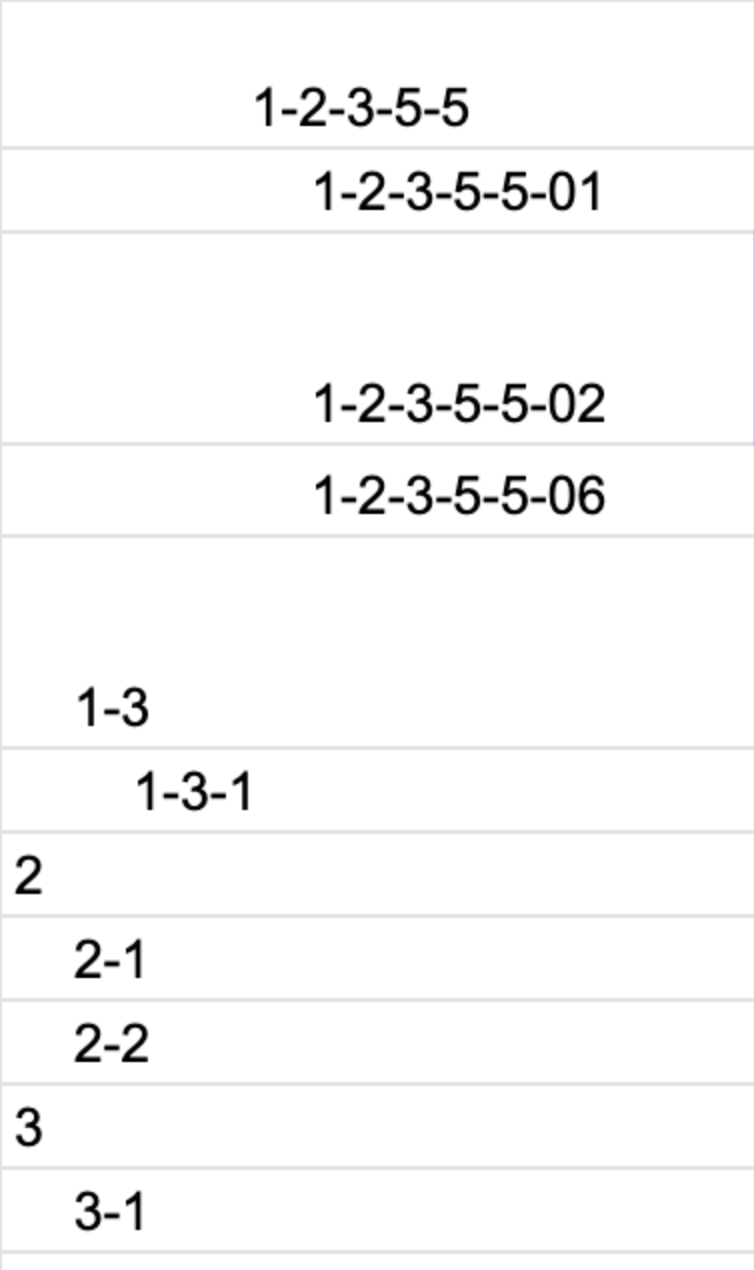
In this clone, we increase learning rate to bounce the blind man out of the hole, so that he can explore other holes.
Exercise 3: Jumping into Holes in Holes
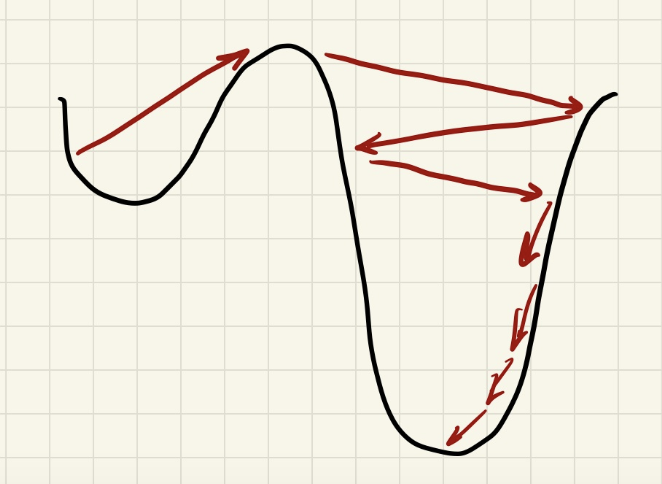
In HW1P2, I feel like this kind of local minima is especially common, where we divide learning rate by 10 in order to fall into the narrower hole:
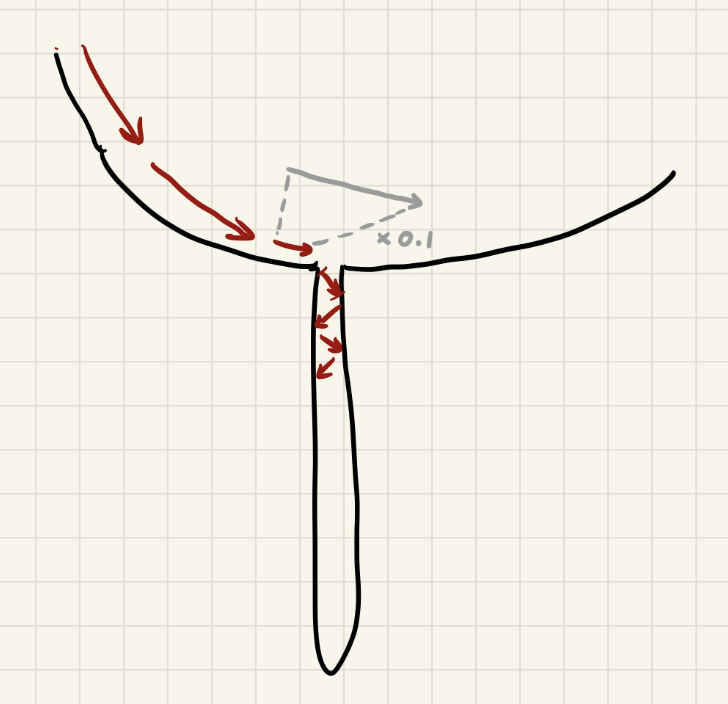
Go up or down? The existence of these hole-in-holes presents an interesting dilemma when we start plateauing. Do we go up, or down? Do we bet that we're sitting on top of a narrower hole, and try to dig down? Or should we bounce out and bet that a deeper hole exists elsewhere?
And when we bounce, how much do we bounce? Do we bet that there's a hole-in-hole in our near vicinity, so we just bounce a little, stay within our hole? Or is our whole hole hopeless, bounce to a whole 'nother hole altogether? (Whole, hole, hope, I sure can alliterate!)
Although textbook advice is to start with a high learning rate and decrease it gradually, usually with the help of a learning rate scheduler, I got better results when tuning manually. Manual tuning was also more tedious, but it was the final thing I tried when I exhausted all other scheduler options.
The learning rate scheduler isn't too good at digging into hole-in-holes, sometimes because it doesn't drop learning rate sharply enough that it wall-jumps over the hole. Sometimes, it simply isn't on top of a hole, and it needs some help bouncing to a better digging spot. When it came to digging into hole-in-holes, I manually dropped learning rate.
And when it came to hole discovery, I preferred cloning a trained model and bouncing it out of its hole, rather than training a brand new model from scratch and waiting for it to converge at a new hole. My reason is that it took less training time and I still saw improvements in accuracy. Since the learning rate scheduler doesn't increase learning rate, it was up to me to increase learning rate, too.
So yes, that's the basic idea! In and out of holes.
My romantic vision of training neural networks was that I'd be nibbling a pear and perusing research papers, hmm, yes, making tasteful architecture decisions. Which, yeah, there was a bit of that, minus the pear.
But my strategy for meeting the cutoff was really pause, adjust LR, resume, pause, adjust LR, resume, sometimes cloning the model in case I was making an risky move with my learning rate. The art of jumping in and out of holes.
Concerns About Reproducibility
If we're going with my "tuning learning rate >> architecture" hypothesis, I feel like reproducibility is a concern.
Even if somebody publishes their tuning schedule, it's not practical to reproduce a training run on the same tuning schedule.
In our deep learning course, students are encouraged to share tips with their study groups on what worked for them. Yet if it turns out that it's tuning that contributes most of the gains, how can we best communicate our tuning strategies?
And when a research paper claims, "We took this architecture, we tweaked it in this way, and we found these changes were super effective," to what extent can we tell whether it's the architectural changes that gave them the benefits, as opposed to their tuning?
My two cents: There isn't really a demand for reproducibility at the moment, I guess. To my understanding, only a small cohort, generally the people at well-resourced organizations, are spending their days training and pushing out large models. Everyone else uses these models. As someone who uses the model, I can't afford the resources to bother with reproducing, and the opportunity cost is high enough that I'd rather use the model. So for the few people training the models, they just need to train good models, don't need crazy guarantees for reproducibility.
I have a few other thoughts that I'm not comfortable expressing publicly as of now. My words are too premature for the internet. That's it for today!
