
The FFmpeg Incident: Open Source Security in the Age of AI-Assisted Vulnerability Discovery
The FFmpeg incident has been blowing up recently in the infosec community. So here's my attempt at describing the incident to a broader audience, since I think it opens a pretty important question about how AI will change the relationship between security researchers and open-source maintainers who depend on their goodwill.
Okay, now to talk about FFmpeg
You've most definitely crossed paths with FFmpeg, if not directly, then countless applications built on top of it. FFmpeg is a library that handles video and audio processing across the internet. Every time you stream a video, convert a file format, or watch content on platforms like YouTube, FFmpeg is likely working behind the scenes.
What's remarkable is that FFmpeg is the result of volunteers. Despite having a reach so vast that its leadership could have monetized it, they chose to keep it free and open-source.
Now, AI agents have gotten really good at finding security vulnerabilities. By summer 2025, the capability had clearly matured. In July 2025, Google announced they'd scaled up Big Sleep and found over 20 vulnerabilities across multiple open-source codebases.
And, as you've guessed, one of those codebases was FFmpeg. Google's Big Sleep agent scanned the FFmpeg codebase and automatically generated vulnerability reports, which then got submitted through Google's Issue Tracker. At least 13 of them, in fact!
Why Maintainers Are Upset
Now, you'd imagine it's a good and wonderful thing when a security researcher points out a security flaw in your system, so you can keep it secure. But...
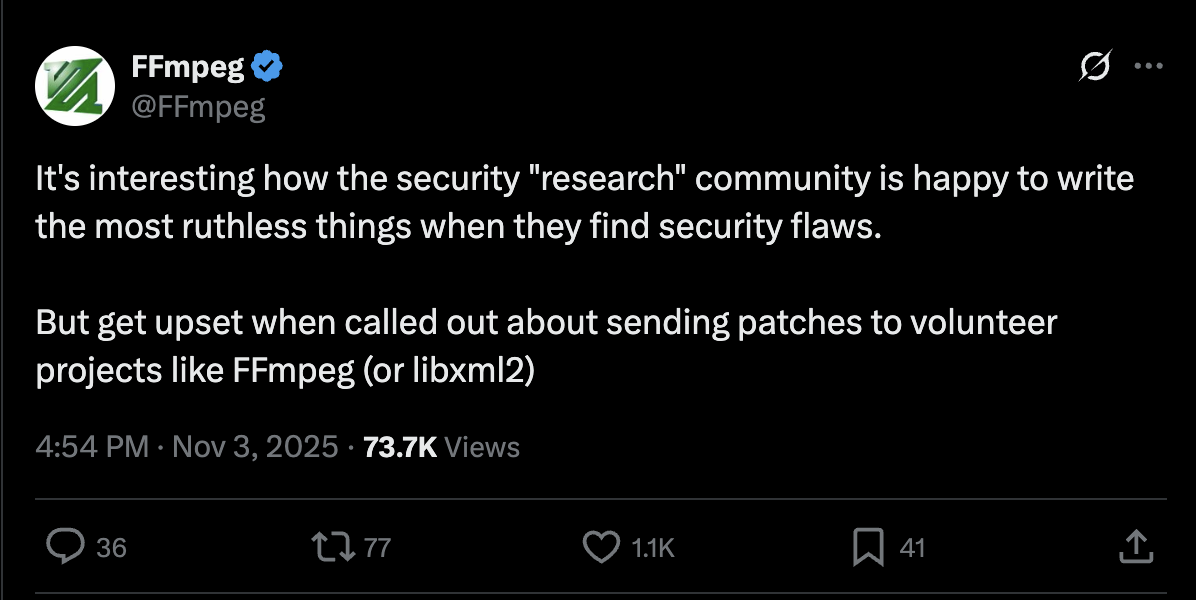
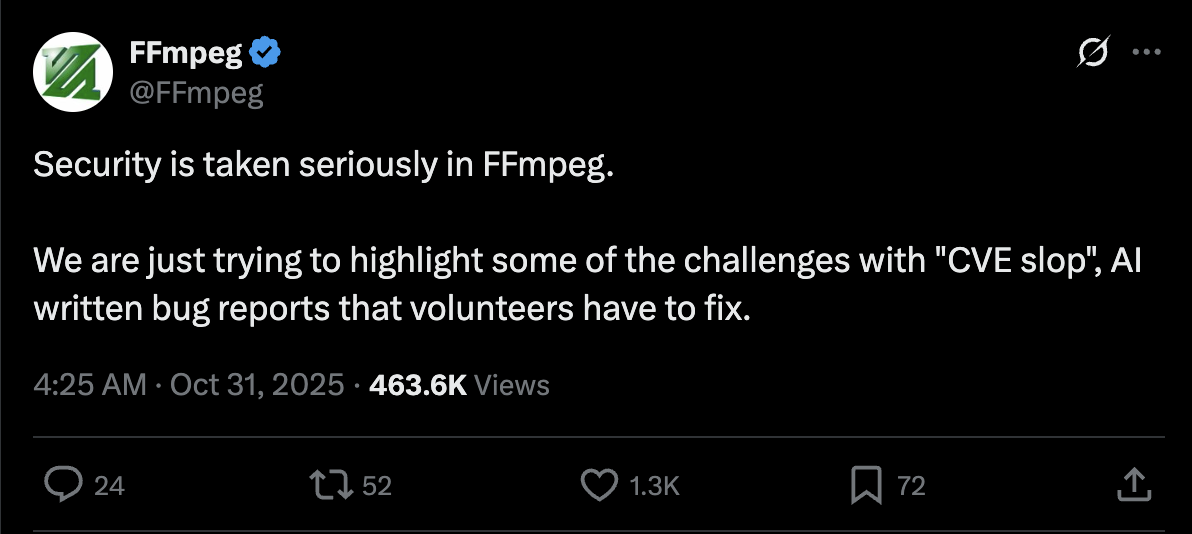 Sources:
Sources: What's going on?
The reason for the upset is due to a mismatch in expectations vs reality of volunteer-maintained open-source projects.
Disclosure Policy, Pre- and Post-AI
For context on the 90-day disclosure policy, when a security researcher submits a vulnerability report, the vendor has 90 days to develop and release a fix. After that 90 days is up, the full details of the vulnerability get published. If the vendor patches the bug before the 90-day deadline, they get an additional 30 days for users to adopt the patch before disclosure.
That policy is reasonable in a pre-AI world where vulnerability discovery was slow and labor-intensive. It becomes a lot less sustainable when AI enables a single researcher to find and generate far more reports that previously would have taken weeks or months to produce.
Professional security researchers, whether at Google Project Zero or independent consultants, typically understand the full context of what they're reporting, and work collaboratively with maintainers to arrive at a fix that doesn't introduce new problems.
Yet the democratization of AI security tools means that most commonfolk can now scan for vulnerabilities and file reports, regardless of their understanding of how critical the vulnerability is or whether it's a legitimate vulnerability, resulting in a lot of AI slop reports. This has gotten bad enough that the open source project cURL has shut down their bug bounty program due to too many false reports that were generated by AI.
So who helps the volunteers work through these reports?
Not the AI agent, it can identify vulnerabilities and propose potential patches, but somebody (a person! "body" as in person!) must go back and forth with maintainers to make sure their patches won't break existing functionality or introduce new issues. And before you say "just have the AI agent handle the back-and-forth with maintainers too," well, when you're a maintainer, the last thing you want to do is argue with a chatbot when you want a person who can be reasoned with and might change their mind.
 You know the dread of calling customer support and getting a bot that doesn't actually solve your problem...
You know the dread of calling customer support and getting a bot that doesn't actually solve your problem...
This can invite resentment from volunteer maintainers, who, from their POV, have been put on a countdown timer to close out the report, with reputational damage if they can't meet an externally-imposed deadline on what is volunteer work and not their full-time job.
From the volunteer maintainer's POV, the security researcher gets to demonstrate their AI capabilities and collect the clout of having found a vulnerability in a commonly-used codebase, while the burden of fixing it falls on volunteers working in their spare time.
From the security researcher's POV, the vulnerabilities are not getting fixed fast enough given the risk they represent, and in the end they're not getting paid out for work that, if submitted to a company with a mature bug bounty program, would have paid out enough to make the hours worthwhile.
It's Just a Rehash of the Engineer-vs-Security Divide, Now With AI
I'm inclined to say that this tension between open source maintainers and security research wasn't invented by AI, but rather brought attention to a cultural difference that already exists between security and engineering.
Even from 2018, there already existed advice columns floating around the tech blogosphere along the ilk of "How to Be a Security Person that Engineers Don't Hate" and "How to be an Engineer that Security People Don't Hate."
Bluntly put, in the tech industry, the security department is often seen as a Cost Center, and engineering as a marginally more redeemable Cost Center that builds the features that customers sometimes or someday hopefully will pay for. So in this light, the security department can be seen as some pesky troll bridge that's standing between engineering and shipping, that exists mostly to cover the company in case something goes wrong later.
 Stop! Who approaches the Bridge of Deploy must answer me These Questions Three, ere the other side he see.
Stop! Who approaches the Bridge of Deploy must answer me These Questions Three, ere the other side he see.
That as long as nothing is going wrong today, the engineering department's priority is on shipping the features that make money and justify the company's existence, don't worry about the hypothetical breach when you got a demo due this week.
While open source doesn't have literal revenue to map this onto, we can see a similar split in how a maintainer spends their time. "Profit center" work is the work that feels generative, like shipping features and improving the user experience. Meanwhile, the "cost center" work feels more hygienic, like bug fixes and dependency updates, that the user won't notice when it's done, but sure as day will notice on the rare occasion it isn't.
So from the POV of maintainer, a vulnerability report looks like any other bug report, except this bug has mysterious special privileges over other kinds of bugs. It has a deadline! And it comes with reputational damage if not fixed! Look at it, all high and mighty with ominous warnings of a security breach and an unflattering headline if we don't act now!
"We Hacked
Insert Name of Your Projectin XYZ Days, Why Don't Maintainers Care About Security?"
Without a way to independently judge how serious the researcher's finding is, it may appear to the volunteer maintainer to be a pesky bug report that gets artificially bumped to the top of the queue, ahead of the other work that they would find rewarding.
Nick Wellnhofer reached a similar conclusion in the months leading up to his stepping down as libxml's sole maintainer. After years of triaging security reports under deadline, he came to the bleak conclusion that the urgency around security was mostly performative, that it lends street credit to the security researcher, but remains invisible to the end user who won't notice whether the fix was shipped in 3 days or 90 or at all.
"The more I think about it, the more I realize this is the only way forward. I've been doing this long enough to know that most of the secrecy around security issues is just theater. All the 'best practices' like OpenSSF Scorecards are just an attempt by big tech companies to guilt trip OSS maintainers and make them work for free."

As of November 2025, libxml2 is without a maintainer.
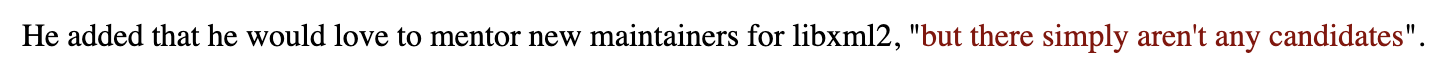
We must rethink how security research and open-source maintenance intersect. There are many volunteer-driven projects that power our infrastructure that may be headed for the same fate, if we don't figure out more sustainable norms around security disclosure and support the people maintaining them.
Can Corporations "Just" Fix This?
A common argument around this is that wealthy corporations should help by becoming maintainers of the open source projects they use. These companies have the resources and engineering talent to maintain the infrastructure they depend on.
This is already a common practice in industry. Big corporations are known to assemble teams of paid employees to drive development of open-source projects. We see this with Meta for PyTorch, Google for Kubernetes and TensorFlow, and Microsoft for TypeScript. It has been very good for the ecosystem.
I agree with these sentiments, but even with backing, our attention as humans has limits. There are only so many hours in a day, and simply hiring more people doesn't fix the problem (more meetings, more handoffs => more chances for the fix to get lost between whoever found the bug and whoever's allowed to merge the patch).
How do we prevent tragedy of the commons? If AI slop makes maintaining OSS unsustainable, what happens to critical infrastructure?
Going Forward
I'm not sure anyone has answers yet, we're early enough in this transition that our norms around disclosure and remediation haven't adjusted to AI capabilities. But we do need to start building norms that consider who is available to respond, and be cognizant when we are reporting to volunteer-led projects, as their time and incentives differ considerably from a paid incident-response team.
We're all in the same boat, just at different points in the dependency chain. The difference is that some of us get paid to ask these questions as part of our jobs, while others are answering them in their spare time, for free, as volunteers for software that the rest of us have built our careers on top of.
I'm realizing now that the volunteers behind the dependencies I'm vetting, the ones I'm scrutinizing for responsiveness and security, are asking themselves the same questions about their dependencies and who they can hand things off to when they need to step away.
If I want responsive maintainers for the software I depend on, then I need to be part of making that responsiveness sustainable.
Postscript: So, About That Exponential Curve
Revisiting this in May 2026, a few things are worth updating.
First, I think it'd be a misnomer to treat the exponential increase in bug reports as permanent.
The influx of reports is really coming from two sources:
(A) piles of legitimate vulnerabilities that went undiscovered for years, that are now easier to mine once you point an AI agent at them. This has kicked off a gold rush for people who want CVEs
(B) AI slop.
After the low-hanging fruit from (A) gets picked clean and the gold rush settles down, we're left with a trickle of legitimate reports and a whole lot of (B). So the question we're dealing with sounds more like "how do we filter out slop from the smaller, steadier stream of vulnerability reports that're left" rather than catastrophizing "oh no!!! reports are going to keep growing exponentially forever and maintainers will never keep up."
Second, an idea I think could be promising
One idea that has been floating around the community, is this: we require vulnerability reporters to pay a lump-sum deposit when filing a report, refunded only when maintainers validate the finding, on top of the standard bug bounty.
I think this could help with filtering out low-confidence, low-criticality reports, provided that the deposit is sized appropriately.
Though, as with any attempt to price something intangible, the devil is very much in the details. I can already picture all the disputes around what counts as "validated," and what is fair pricing, and the greater urgency it puts on maintainers and reporters both when the latter's money is held hostage.
Finally, on a happier note, the ecosystem has moved in a good direction since I wrote this.
FFmpeg and cURL maintainers have warmed noticeably toward vulnerability reports, and researchers are more vocal about submitting patches alongside their findings. I'm glad to see this. Onwards~
