
Deep Learning 3/N: Sequence Modeling
I'm actually lumping two posts in one, HW3 (sequence learning using RNNs, GRUs, LSTMs), and HW4 (sequence-to-sequence modelling using transformers).
The reason being, for HW3 I didn't have much new to add in regards to training, as I reached the high cutoff using same techniques as before.
My beliefs have settled along the lines of the post, The "it" in AI models is the dataset. To quote,
Trained on the same dataset for long enough, pretty much every model with enough weights and training time converges to the same point...Then, when you refer to “Lambda”, “ChatGPT”, “Bard”, or “Claude” then, it’s not the model weights that you are referring to. It’s the dataset.
I highly recommend the nonint blog! It offers fresh insights I haven't seen in a while.
And an update to my questions about reproducibility from my part 1 post on HW1, this nonint post answered it. In short, the blog answered many of my questions and put into words some thoughts I've had for a while.
Since I don't have new insights for training, I thought of explaining the architecture. But! This would be a summary of the homework handouts and textbooks, and I firmly believe that I don't want to summarize. Whatever I write about should come from my own experiences.
So, I decided it would be best to wait until HW4, which is like a successor to HW3 and by extension, HW1 also.
I do think I'll find something new from this-- namely, before this unit, I didn't have intuition for why transformers were so great and how they were fundamentally different from other sequence models, and I expect I'll understand how by the end.
Stay tuned, and in the meantime enjoy the nonint blog I linked. :)
Also, today is my mom's birthday so happy birthday mom. She doesn't know about my website but next time you see her, you can tell her she's like, totally a Scorpio. You can say you're good at deducing people's birthdays :p

Speech Recognition
November 21, 2024
You know those didactic stories that come in threes? Three sons, three daughters, three huntsmen, three whatevers trying to accomplish a task?
The eldest son attempts the task and it's an okay start, the middle son ekes out some more success, and finally the youngest saves the day.
Well, HW1, HW3, and HW4 are our three sons, and the task they're tackling is speech recognition.
- The eldest son is HW1,
- The middle son is HW3, and
- The youngest son is HW4.
Now, as audience members watching a show, there's a tendency to underestimate the difficulty of the task. You see contestants running through an obstacle course, and you go, "I could've done that." You see a chef get critiqued on their cooking, and you go, "I could've done that." Just grab the bullet and throw it back. Tap, tap, grab the bullet, throw it back!
We're going to dispel that right now.
This is a Mel spectrogram of the word "yes." You take the sound recording of a person saying "yes," apply some transformations, and there we go! It's the Mel spectrogram of the word "yes."
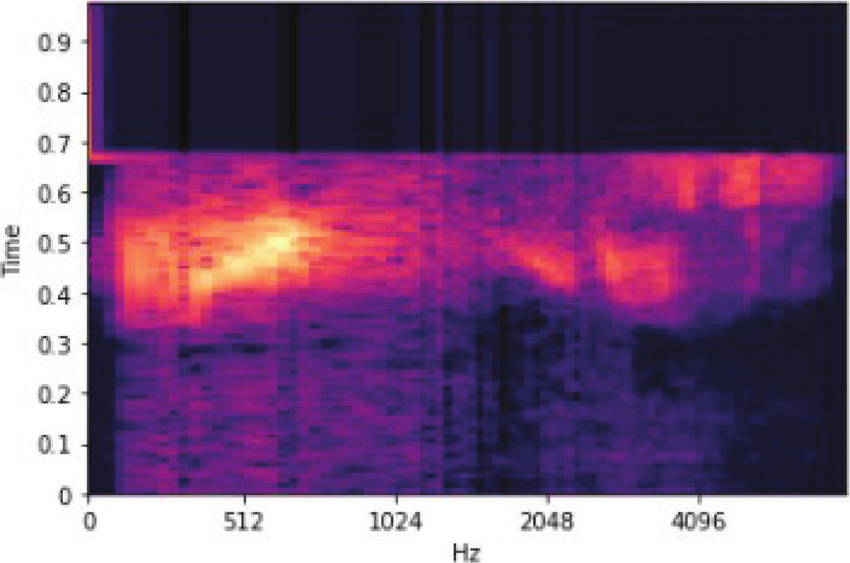
That there, the sequence of mel spectral vectors, is the input for our three sons, produced by slicing our speech into frames and computing mel spectral vectors for each frame.
Can you tell that it's the word "yes"? No?
Well, neither can the three sons, and that's what they're trying to do.
 When I ask my models why their error rates aren't going down, I pull up a picture of a spectrogram and ask myself, "Can YOU tell what English sentence this is supposed to be? No? Well, then, a 12% error rate's not bad, is it?!"
When I ask my models why their error rates aren't going down, I pull up a picture of a spectrogram and ask myself, "Can YOU tell what English sentence this is supposed to be? No? Well, then, a 12% error rate's not bad, is it?!"
The eldest son is HW1, a simple MLP. He labels each frame with a phoneme, one phoneme for each frame, to get /Y/ /Y/ ... /Y/ /EH/ /EH/ ... /EH/ /S/ ... /S/.
The eldest son does not care how he labelled surrounding frames. If he's convinced that a frame in the "e" part of the recording sounds like an /OY/, he may very well come out with /Y/ /Y/ ... /Y/ /EH/ /OY/ ... /EH/ /S/ ... /S/, never mind the fact that the /OY/ is sandwiched between a bunch of /EH/'s.
The middle son is HW3, a recurrent model with a postprocessing step. Like the eldest son, he labels each frame, but he labels each frame with the probabilities that it can be each phoneme. And when he labels frames, he takes into account surrounding frames, both preceding and succeeding.
Even better, the middle son values cleanliness, decoding his final answer into /Y/ /EH/ /S/. With great discernment under the Beam Search algorithm, he decodes the alphabet soup of phonemes and probabilities into /Y/ /EH/ /S/.
The youngest son is HW4, the transformer. He takes the frames and directly spells it out in English text as "yes"!
The crazy part about the youngest son is that he doesn't label each frame with phonemes, or at least there's nothing in his architecture telling him to do anything related to phonemes. The other crazy part is that he can look at frames all at once, not step-by-step like the middle son, so he can solve problems that have no input-output correspondence.
So, how does he do it?
Peeling Back the Analogy
To understand the middle son, the recurrent model, read this overview of RNN, LSTM, and the attention mechanism. In HW3 specifically, we used a bidirectional LSTM, which is essentially a pair of LSTMs, one forward and one backward, that let the middle son infer on both preceding and succeeding data in the input, as opposed to just preceding data as one would with a single LSTM.
The middle son is the diagram to the left, the vanilla encoder-decoder architecture without attention.
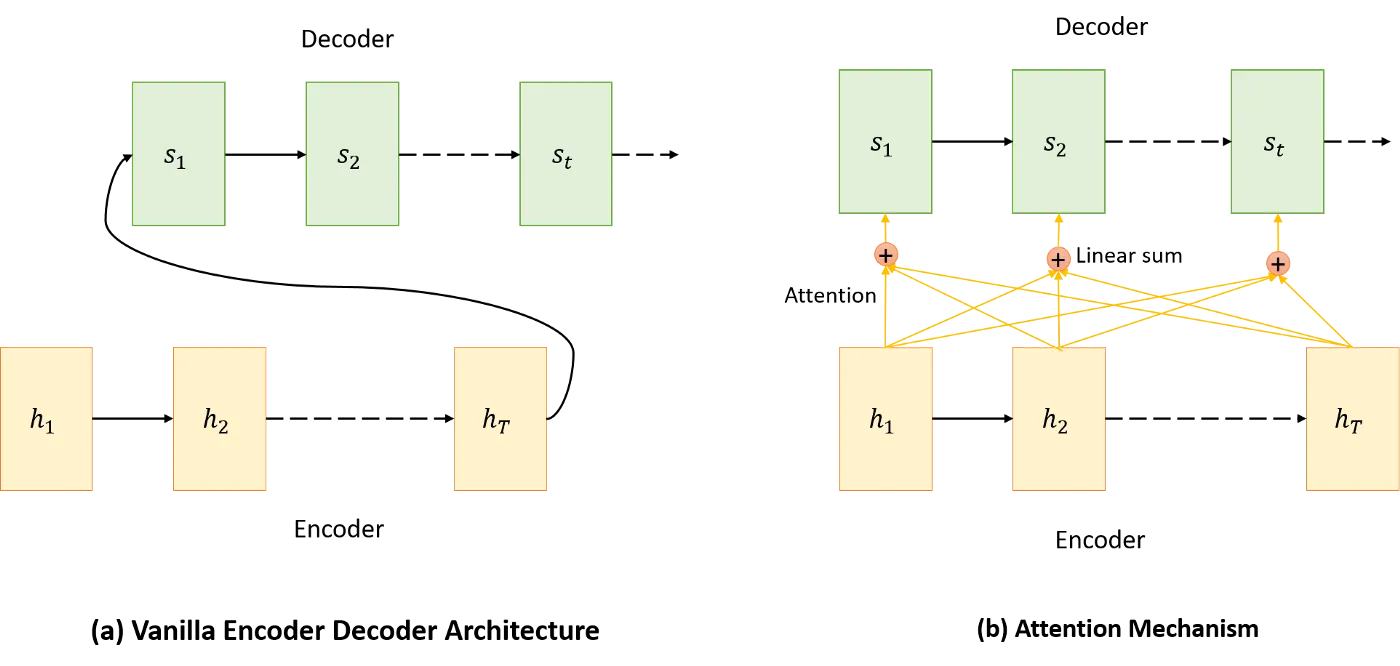
A caveat of the left architecture is that the middle son is pressured to cram the entire input sequence he's seen thus far into a single hidden unit. As the input sequence gets longer and longer, the middle son forgets information near the beginning of the sequence.
As a result, the middle son is best suited for tasks with time synchrony, where the order of input elements roughly matches the order of output elements.
For example, translating the English sentence "eat an apple" into Pig-Latin "eatyay anyay appleyay" is time synchronous, as the original words appear in the same order as the translation.
It's not an issue if we're translating a longer sentence "blah blah blah ... eat an apple" and we forget the blah blah blah because our ability to translate "apple" into "appleyay" depends more on recent information anyways, like the "eat" to tell us that "apple" is a food, or "an" to tell us apple is a noun.
However, for tasks without time synchrony, where the order of input and order of output elements aren't related, this forgetting can be an issue, as the most relevant information may be long forgotten.
For example, translating the English sentence "eat an apple" into Japanese "リンゴを食べる" does not have time synchrony, as the Japanese sentence literally translates back to the scrambled "apple of eat." If the sentence is longer, like "blah blah blah ... eat an apple," it's very likely that our desired contextual information is in the forgotten blah blah blah. As such, the task of translating English to Japanese would suffer from forgetting as sentences get long.
 This is why we don't have real-time translators for Japanese-to-English. We have to wait until the end of the sentence!
This is why we don't have real-time translators for Japanese-to-English. We have to wait until the end of the sentence!
And so, attention was introduced, in the diagram on the right. Instead of predicting based on the most recent hidden state, we look at all hidden states calculated thus far, and we decide how much significance to place on each by calculating attention weights.
The youngest son, the transformer, came about when someone had the radical idea of taking the recurrent-neural-network-with-attention architecture, and keeping attention but removing the recurrent aspect. This was the gist behind the paper Attention is All You Need.
The really powerful part of the transformer is that it can solve problems without input-output correspondence. No longer limited to problems that have time synchrony, the transformer can be used for problems where the input is something like, "Tell me a joke," and the output is, "Why did the chicken cross the road?"
I believe this is why we see transformers everywhere, the fact that they're unshackled by the need for input-output correspondence. Although transformers originated in machine translation, they've found their way into all sorts of problems in deep learning, from computer vision, to reinforcement learning, to generative modelling, and cross domain into protein folding.
For a high level overview of the transformer, watch 3Blue1Brown's explainer. To set the context for the rest of this post, should understand (1) tokenizing the input, (2) encoding tokens into vector embeddings, (3) attention mechanism, (4) decoding vector embeddings.
Optional: If you're wondering how a transformer "knows" where in the original sequence each input element appears, this video wonderfully illustrates positional encoding.
Another Word on Threes
This is the third time I've implemented a language model. The first time was through Andrej Karpathy's video series. The second time was through a separate tutorial series, to implement an RNN with the attention mechanism. And the third time was through 11785.
The dastardly part of watching a video, or of following a tutorial series, is that I feel like I get it. My eyes understand the pretty animations, my ears understand the words being said, and if it's a code-along video, I follow along each step and my results match the results in the video, so I think I get it.
This third time around, I still had moments that made me realize I didn't actually understand, when I missed certain implementation details and corrected them to get over snags in training.
A new standard I hold for myself on blog posts is that I want to write generalizable things. So instead of listing observations w.r.t. training and implementation that may or may not generalize to other problems, I want to distill them into 1 or at most 1.5 takeaways that may be of use.
The other standard I hold for myself is that I won't write about something that I didn't experiment with myself. These experiments may not be related to the original homework assignment, HW4, but more like tangential explorations.
As such, the time I publish the rest of this post may be well after December 6th.
I'm still running some experiments for HW4, so I'll wait until all of that is done (after December 6ish) to write it up.
Extra Explorations
November 24, 2024
Final installment for this post, I promise! As I was drafting this subpost, I noticed it splits off into a separate topic altogether, retrieval augmented generation (RAG). I decided it would be better to publish the half that's related to transformers here, then save the RAG half for a separate post.
In addition to meeting the homework requirements, two areas I wanted to explore more of were
- Tokenization, the alleged footgun of language models
- Encoder-Decoder vs Decoder-Only Architecture
Tokenization
Tokenization is like the boogeyman for language model failings. GPT can't do math! GPT can't count the number of Rs in STRAWBERRY, GPT thinks there's only two Rs in strawberry! GPT could answer this question, until I spelled it differently and then it broke!
These failings, according to deep learning experts, point back to the boogeyman of tokenization, and so I wanted to explore tokenization in some capacity.
On a high level, I could see that, yes, tokenization should affect model performance in some way. Essentially, tokenization is how we break our input text into smaller units called tokens. Our model then learns the meaning of these tokens, by learning how to represent them numerically as vector embeddings.
So, on a high level, I could see how if our tokenizer sucked, then our model would struggle to making meaning out of the tokens.
Beyond the high level, I was looking for a concrete way to compare the "goodness" of two tokenizers, and I found my answer in the Embeddings section of this cybernetist blog post. Basically, to evaluate how "good" a tokenizer is, you can take your model's vector embeddings for two inputs and calculate their similarity score. Ideally, if sentence A is a typo of sentence B, you'd want their similarity score to be high, a sign that your model successfully identifies them to carry similar meaning despite the typo. And if sentence A has some small differences from sentence B that change its meaning, like "You can break it easily 😞" vs "You can not break it easily 😊," ideally you want your model to have very different embeddings for the sentences.
This method of comparing similarity of vector embeddings is like a proxy for tokenizer performance. If our tokenizer is "good enough," then our model will have similar vector embeddings for similar-meaning inputs, and vice versa for dissimilar inputs.
Within the scope of the homework, I used the character tokenizer, which, as the name suggests, breaks inputs into characters. I tried other tokenizers but didn't see a visible advantage over the character tokenizer, so I stuck with the character tokenizer.
I would guess that the choice of tokenizer matters more for larger language models, where emergent abilities like solving math problems or counting the Rs in STRAWBERRY could be more heavily affected by tokenization. It's great that the tokenizers of most frontier models are open-source to help us with fuzzy debugging.
Tokenization is a whole rabbit hole that can be revisited in the future. Namely, when we're developing a system with a language model and the model produces bizarre results, we can consider tokenization a culprit and think about how to reformat our input to be more tokenizer-friendly.
Encoder-Decoder vs Decoder-Only Architecture
The other point I wanted to discuss was encoder-decoder vs decoder-only architecture. When I mentioned that there were concepts I "thought I understood," then implemented them and realized I didn't, this was one of them.
Our architecture is actually two models in a trenchcoat:
- The encoder: transforms inputs into embeddings.
- The decoder: takes embeddings and generates an output.
For generative tasks like generating English sentences, the decoder alone is sufficient. The encoder is more like an add-on for tasks that require an enhanced understanding of input data, like machine translation, or in our case, speech recognition.
Question: How is using the encoder to produce embeddings any different from, well, using a single embedding layer (like PyTorch's nn.Embedding, or TensorFlow's tf.keras.layers.Embedding)?
Answer: Now we get more into the weeds. To my understanding, an embedding layer is internally just a single linear layer, and this is true for Tensorflow's Embedding layer as well. To my understanding, neither of these embeddings use the attention mechanism in any form.
Meanwhile, our encoder is not a single linear layer, but instead a transformer model. In essence, it's a bunch of encoder layers stacked together, with each encoder layer having a self-attention module.
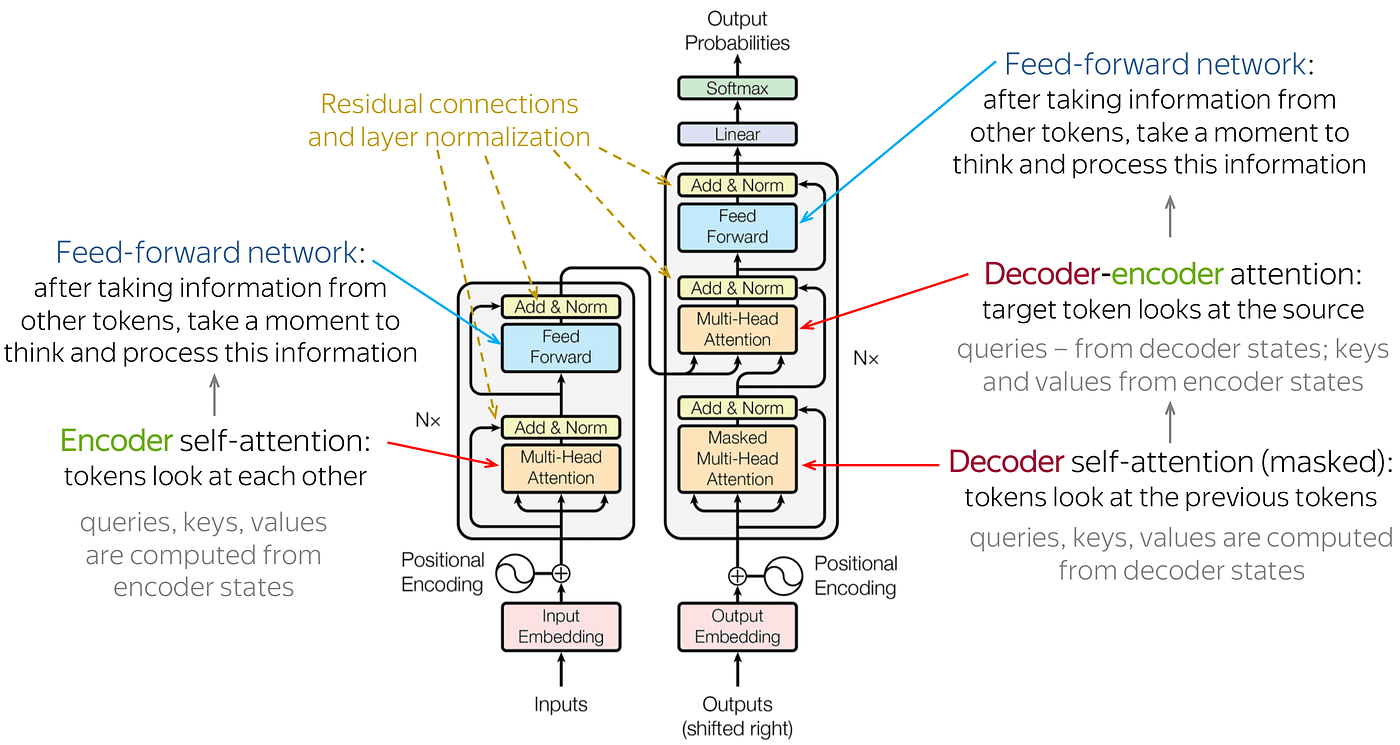 See diagram to the left for an example of a single encoder layer.
See diagram to the left for an example of a single encoder layer.
The "it" factor of the encoder is in the self-attention mechanism that gets applied with every encoding layer.
Question: Doesn't the decoder also have a self-attention mechanism?
Answer: The encoder attends to both the past and future, while the decoder attends to only the past.
Since "decoder attends to only the past" sounds super woo-woo mystic, let's zoom in and discuss an implementation detail that'll explain what this means.
To set the context, the decoder is trained independently in a separate pre-training step. After the decoder has trained some amount, the encoder and decoder are trained together in a full training step.
When it comes to pre-training the decoder, the implementation detail that puzzled me at first was the presence of a golden target and a shifted target. The target is the desired output text we want for a given input. In short, the golden target is the tokenized target with a special end-of-sequence token <EOS> appended, while the shifted target is the tokenized target with a special start-of-sequence token <SOS> prepended.
Question: Why do we have a golden target and a shifted target?
Golden target:
H E L L O <EOS>Shifted target:
<SOS> H E L L O
My original mental model of training the decoder was that it would be
Input: Our audio embeddings, post-processed ,> Target:
<SOS> H E L L O <EOS>
Answer: When I revisited how the decoder generates text, the less I realized my previous mental model made sense. At heart, the decoder generates text by taking the sequence of tokens it has generated so far and predicting the most probable token that'll follow.
So, the inputs to the decoder are its past outputs.
As such, if we want to teach the decoder to generate <SOS> H E L L O <EOS>, we want the decoder to learn that
<SOS>predictsH,
<SOS> HpredictsE,...
<SOS> H E L L Opredicts<EOS>.
We can think of the golden target H E L L O <EOS> as the thing we're predicting, and the shifted target <SOS> H E L L O as the thing we're predicting from.
The golden target and shifted target aren't actually what we feed the decoder. We actually feed it something along the lines of
([<SOS>, 0, 0, 0, 0, 0], H),
(<SOS>, H, 0, 0, 0, 0], E),
...
([<SOS>, H, E, L, L, O], <EOS>)
where the suffixes of the shifted target are masked out with 0's to tell the decoder to ignore those parts. The mask we use to mask out the suffixes is called the "causal mask."
[Skip to "Why We Need Encoders"] Midnotes on the Causal Mask
I didn't want to put these at the bottom as footnotes, since I like posts that end gracefully. I like scrolling to the bottom of a page and landing into the warm welcoming arms of a grand conclusion, and a pet peeve of mine is scrolling upwards because I fell into a dumpster of footnotes instead.
Also, a reason I don't read footnotes is because by the time I've reached the bottom of the page, I've lost context for when the footnote was made. Another peeve of mine is rereading the surrounding text to refresh myself on the context of the footnote.
So, reader, while you still remember the context for my midnotes, here they are.
Note on teacher forcing: The shifted target, <SOS> H E L L O, is crucial for training. When the decoder is still learning, it's very, very likely to predict the wrong token for a given input sequence.
Suppose it predicts A from the input <SOS> H, when it was actually supposed to predict E. When it comes to predicting the next token L, we still want it to learn from the sequence <SOS> H E, rather than its incorrect <SOS> H A.
This idea of feeding the desired output, aka the ground-truth sample, back into the model after every step, is called "teacher forcing."
Note on training in parallel: It may sound like we teach the decoder sequentially, that it predicts H from <SOS>, followed by E from <SOS> H, and so on. The decoder actually learns these samples together, in one grand conglomerate tensor.
([<SOS>, 0, 0, 0, 0, 0], H),
(<SOS>, H, 0, 0, 0, 0], E),
...
([<SOS>, H, E, L, L, O], <EOS>)
Note why <SOS> token instead of empty sequence: The <EOS> token made sense to me, but I was puzzled by why the <SOS> token existed.
I understood that the <SOS> token was necessary for the decoder because at the very beginning, it needs some sort of input to start with.
However, I wondered, why not an empty sequence, or hard-code an input for the decoder to start with? To my understanding, the benefit of having an <SOS> token is that we provide the decoder with some sort of initialization.
Recall that our model learns vector embeddings for each token. With the existence of an <SOS> token comes a vector embedding for this <SOS> token, and it may be well worth learning some sort of "optimal" representation for this vector embedding, rather than hardcoding it as zero or randomly initializing it.
Moreover, we can customize different types of start tokens for different types of tasks. Looking at models like GPT and Llama, they don't have one <SOS> token, but instead have different kinds of start tokens for different kinds of tasks, usually a <user>, <system>, and <assistant> tokens for user input, system-level instructions, and the chat assistant's response respectively.
Why We Need Encoders
So, when we revisit the question, "Doesn't the decoder also have a self-attention mechanism? Why use the encoder?" The decoder performs self-attention on masked input, specifically masked with the causal mask, while the encoder performs self attention on the full input.
The decoder attends to only the past, while the encoder attends to both the past and future. Recall again our example of English-to-Japanese translation, and the lack of time synchrony of that translation task.
The decoder is good enough for most generation tasks, but in situations where we'd like some information about the future, we can use some help from the encoder.
See diagram to the right for an example of a single decoder layer.
This is a great time to point out another difference between encoders and decoders, and it's that in addition to a self-attention module, each decoder layer has a cross-attention module, which calculates attention between (1) the decoder's outputs thus far, and (2) context provided by the encoder's embeddings.
For the attention mechanism, I like to think of query, key, value in terms of "the self" and "the other." I like to think of query as the self, while key and value are the other.
We're trying to update our self based on new information provided by the other. In papers, you'll see this referred to as "conditioning on" the other, like "we're conditioning on so-and-so features" or "attention conditioned on so-and-so features."
To sum up,
- query is our self. This is the thing we're trying to update based on new information.
- key and value are the other. This is the provider of new information. Some people like to talk about key and value like key-value pairs in a dictionary, like key is the word you're looking up, and value is your desired information. This dictionary analogy is not intuitive for me; to me, both the key and value are used for lookup, and your desired information is something else. So, I think of the key and value as a pair of magical vectors that when combined together, tell us something about the other.
Self-attention is when we're conditioning our self on our self. Our query, key, and value come from the same input vector. This is not to say that the query, key, and value vectors are the same. They're obtained by multiplying the input vector with matrices W_Q, W_K, and W_V respectively, and a goal of training our model is to learn the magic values for these matrices W_Q, W_K, and W_V.
Cross-attention is when we're conditioning our self on some other. Our key and value come from an input vector that's different from our query. In the case of our speech recognition task, our key and vector comes from our encoder's vector embedding of our audio spectrogram, while our query vector comes from the English text that our decoder is generating.
Below is an animation that should clear up how our output <SOS> H E L L O <EOS> is generated from feeding audio vectors to the encoder and a starting token <SOS> to the decoder.
When would we use decoder-only architecture?
A huge surprise for me was this:
Most frontier models use decoder-only architecture.
That's right, the whole GPT family is decoder-only, Claude is decoder-only, etc.
For all the benefits we discussed about encoders, why don't these commercially successful language models use encoders in their architecture?
After reading papers about "should you use encoder-decoder or decoder-only architecture," and blog posts by likemindedly puzzled people who cited more papers about "should you use encoder-decoder or decoder-only architecture," the most convincing answer I've arrived at is that training becomes less efficient.
The first answer I thought of was, well, inference for encoder-decoder architecture is probably slower. If we're passing through an encoder, then we'll wait longer before we get a generated response. The blog posts I linked also brought up the point that we miss out on various optimizations when we use encoder-decoder architecture. With decoder-only architecture, recall that the self-attention mechanism of the decoder layers is on past tokens only, due to the causal mask. Hence, in decoder-only architecture, we can reuse cached attention values, as they remain unchanged due to each position attending only to previous tokens.
But I wasn't convinced by this answer, as I didn't think slower inference was a dealbreaker. For example, Google Bard is an encoder-decoder model, and I didn't feel like it was significantly slower than the decoder-only models in a way that would turn users away from it.
The answer that I'm convinced by is that training becomes less convenient for encoder-decoder architectures. Speaking from my experience with HW4, we pretrain the decoder for 10-20 epochs, then we train the encoder and decoder together for 100 epochs.
Based on the contrast of 10 epochs for decoder, 100 epochs together for HW4, I can imagine that if we were to finetune the decoder on a new dataset, we would have to tune the encoder to accomodate for the changes to the decoder, and this would take significantly more time than training the decoder alone.
When you adopt lil' bear, you're also adopting mama bear. Adorable, sure, but they train slower together.
Encoder-Decoder vs Decoder-Only for RAG Systems
Now a segway into my next planned post, something I'm exploring is retrieval augmented generation (RAG), which is the idea of supplying language models with documents ("retrieval") that they may not have necessarily been trained on ("augmented"), as a way of enhancing their ability to carry out your task.
If the documents in our data store don't change often or change very slowly, I wonder if it's worth using an encoder-decoder model for RAG and fine-tuning the encoder occasionally.
