
Inference Engines 3/N: Speculative Decoding
Good news, this post is self-contained, but if you're curious where we came from, the series starts at 0/N.
- Inference Engines 0/N: Foundations
- Inference Engines 1/N: KV Cache
- Inference Engines 2/N: Batching and PagedAttention
- Inference Engines 3/N: Speculative Decoding <- we are here
The Open Frontier - original research that builds on this Inference Engine series.
- The Open Frontier 0/N: Who, what, Qwen, and why?
- The Open Frontier 0.5/N: I Probed an MoE Model and Mostly Just Learned How MoE Works
Review of Phases 2 and 3
By end of Phase 3, we were able to serve many concurrent sequences from many users at once pretty efficiently.
But, look at the per-token latency number from all of Phase 1 through 3...
Is this as good as latency gets?
30 ms/tok, 30 ms/tok, 30 ms/tok, huh! Thirty, trente, treinta...
Our latency hasn't budged one bit. It seems that at best, our users must wait 30 ms or worse for each token.
At this point, we may have retired ourselves to the idea that our goal is to protect this 30 ms/tok, that in an ideal world, if we can improve our other numbers without worsening this 30 ms/tok latency, we are a success.
Today, I have good news for you, that we do have a technique to make this number go down. That technique, my friends, is called Speculative Decoding. :)
Speculative Decoding: Or, the Art of Delegation
The intuition behind speculative decoding is that we have a large model, the target model, and a smaller model, the draft model. Our target model is slow at generating tokens because we need to load, say, several billion weights of its own weights into memory per token. Meanwhile, our draft model, being tinier, has less weights to load, and thus can generate tokens pretty fast.
Alas, our target model is slow, and it hasn't yet started writing that paper for that conference whose submissions close next week. What is our target model to do?

Well, let me introduce you to the law of proofreading: this idea that it is faster to read than it is to write.
So what if the target model just... delegated the writing to its smaller yet faster grad student, the draft model? The draft model writes out a few paragraphs, and the target model skims through, nodding or crossing things out.
The target model's primary job to read (fast!), while rewriting (slow!) just enough to fix the parts that are wrong.
"Faster to Read Than Write"
Speculative decoding is founded on this idea that our target model can verify K tokens in roughly the same amount of time as it would've taken to generate 1. Why is this true?
This is because decode is a memory bound operation. In other words, the cost of decode is dominated by our ability to load data into memory. Since decode only processes one token at a time, the cost of loading the weights into memory dominates the cost of the actual computation for that token. So, no matter how many clever arithmetic tricks we hypothetically discover for speeding up computation, our model can't go faster because memory bandwidth is the bottleneck, not compute.
Contrast this with a compute bound operation like prefill. Prefill is not memory bound because it processes many tokens at once for the same loading of model weights. As a result, this cost of loading weights gets amortized across tokens, so the cost is no longer dominated by loading data from memory but by the computation itself across all K tokens.
So, in speculative decoding, the verification step, where the target model checks all K draft tokens at once, is fast for the same reasons that prefill is fast, as it's a compute bound operation.
More formally, the algorithm for speculative decoding is as follows:
- Use a tiny fast draft model to speculatively generate K tokens, aka guess what the target model would've written.
- Run one target model forward pass to verify all K tokens at once, to confirm "yes, indeed, this is what I would've written."
- Accept tokens where the target agrees. At the first disagreement, take the target model's correction and discard the rest.
If the draft model guesses right 80% of the time, we get roughly 4 tokens worth of output per target model call instead of 1. As such, the success of speculative decoding is hinged on the selection of a really, really good draft model.
Phase 4, Step 1: To pick a draft model
Commit: fcefbd2
We're looking for a Goldilocks draft model, one that thinks similarly enough to the target that it earns a high acceptance rate, but small enough that its per-token latency gives us meaningful savings. If it's too similar in size, then the draft step wastes time for very little speedup. If it's too different in reasoning style that our target rejects most tokens, we'd have been better off just calling the target directly.
Since our target model is Qwen3-4B, a pretty natural place for us to start would be to pick a smaller model from the same family, like Qwen/Qwen3-0.6B.
Must the draft model come from the same family?
What if we can't find a smaller model from the same family? Must the draft model come from the same family?
Well, yes and no. The draft model just needs to use the same tokenizer, which often but not always means coming from the same family. This is because the draft and target must use the same vocabulary; otherwise, the draft's token IDs mean something different to the target.
Swapping tokenizers is technically possible but somewhat painful. You could perform a "tokenizer transplant" if you so wish, lobotomizing a small, fast model and re-embedding it to your target model's vocabulary, but this typically requires extra fine-tuning on your end to recover lost quality.
So in practice, same-family models are strongly preferred, even though the only hard requirement is to share the same tokenizer.
Let's do some benchmarking and decide from there whether we want to go bigger/smaller from 0.6B.
Below, we wrote a profiling script that loads both Qwen/Qwen3-0.6B (draft) and Qwen/Qwen3-4B (target) on the same GPU. It runs the same prompt through both models and measures the per-token latency of each model.
modal run modal_run.py::profile
Running latency profile on A10G (new_tokens=128)
model tok/s ms/tok (mean) ms/tok (p50) ms/tok (p90) TTFT (ms)
------------------------------------------------------------------------------------------
Qwen/Qwen3-0.6B 45.3 22.09 22.09 22.40 25.0
Qwen/Qwen3-4B 33.4 29.92 29.88 30.40 31.8
target / draft latency ratio: 1.4× (draft is 1.4× faster per token)
So, it looks like our draft model averages about 22 ms/token, while our target model averages 30 ms/token.
Given this fact, two good questions for us to ask are:
-
What's the best we could possibly do with speculative decoding on this hardware, and
-
What's the minimum acceptance rate our draft model needs to achieve before speculative decoding is worth enabling?
Q1: The Ideal Case
Starting with the first question, suppose we live in the perfect world where our target model accepts our draft model's tokens 100% of the time. At best, how much would latency decrease with respect to K (number of tokens that the draft model proposes at a time)?
Let's do a little math, and let's call LatencySpec the per-token latency of speculative decoding, and LatencyTarget the per-token latency of our target model before any speculative decoding improvements.
Then our ideal latency after speculative decoding would be:
LatencySpec = time spent decoding / # of tokens decoded
= (K * LatencyDraft + LatencyTarget) / (K + 1)
If you're wondering where the K + 1 generated tokens comes from, I hope this diagram clarifies things.
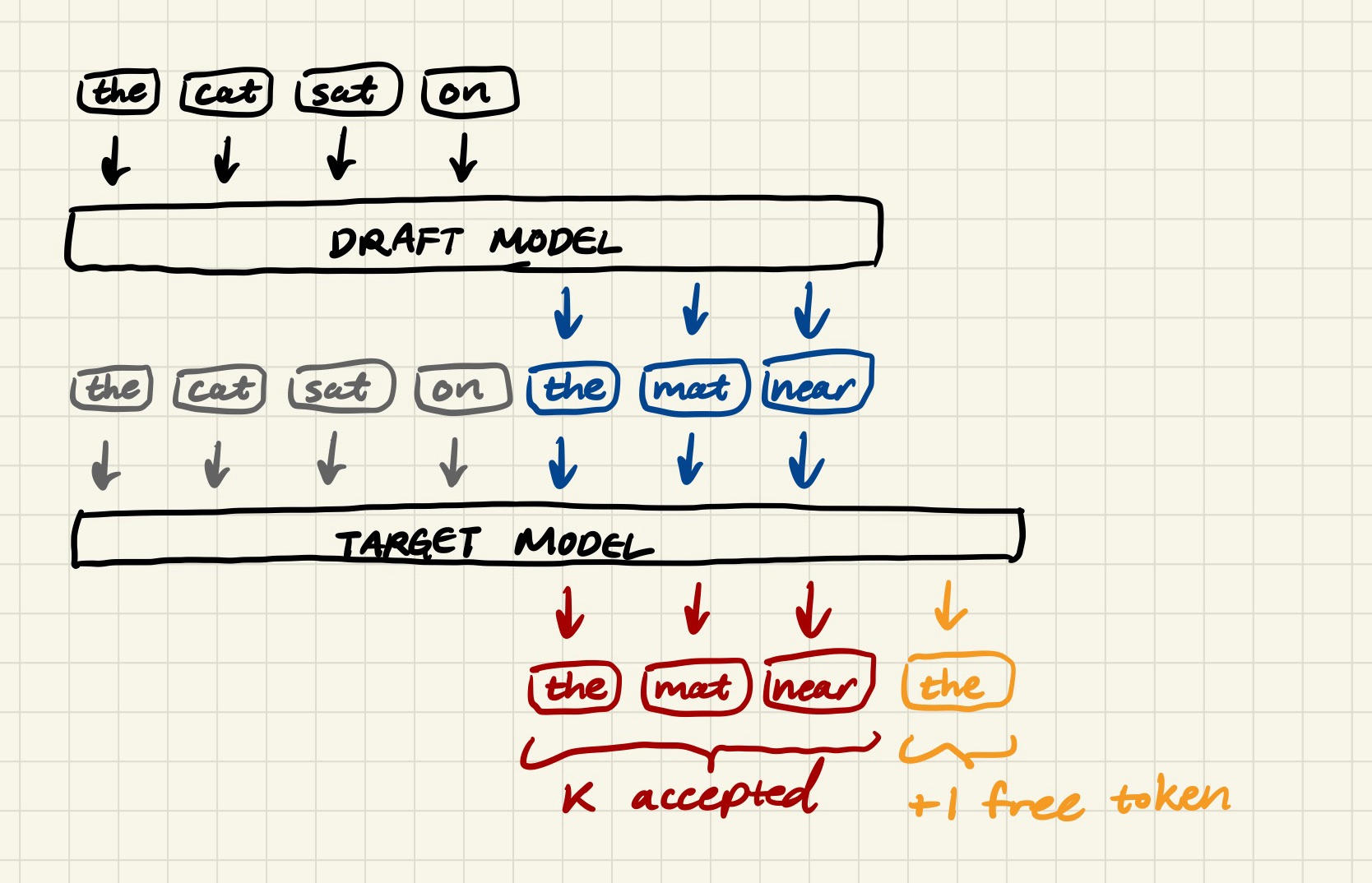
Where does the +1 token come from?
Basically, the target model runs one forward pass over all 7 tokens (aka the 4 original inputs plus the 3 draft tokens) simultaneously. At each of the 3 draft positions, it produces a probability distribution and checks whether the draft token falls within it. If yes, it accepts that token.
At the final position, after the last draft token, it produces a distribution with no draft token to check against. So the +1 is a "free" output token of sorts, a byproduct of the target model's verification forward pass and not an extra decode step.
This means that when the target model accepts all K tokens, we actually get one extra output token for free. :)
So, plugging in our equations for LatencySpec (ideal latency after specdec) and LatencyTarget (latency before specdec), our best possible speedup for each K should be the following:
K expected_tokens ms/tok (spec) speedup
-----------------------------------------------
1 2 25.51 1.17x
2 3 24.70 1.21x
3 4 24.15 1.24x
4 5 23.77 1.26x
5 6 23.49 1.27x
6 7 23.27 1.29x
8 9 22.95 1.30x
10 11 22.73 1.32x
Q2: Breakeven Acceptance Rates
But real life is not always this rosy. Our draft model is bound to disagree with the target sometimes, and each rejection means we spent a little more compute on our draft without producing a token.
Given this, for each K, what is the "breakeven" acceptance rate, that is, the minimum acceptance rate (α) our draft model needs to achieve in order for speculative decoding to truly be an improvement over target-only latency?
We'll solve for the breakeven α under the premise of setting our speedup to 1x; in other words, the point at which where speculative decoding is just as fast as not doing speculative decoding at all. Below is the math:

For K >= 3, no nice closed-form expression for α exists, so we whip up a handy numerical solver for calculating the remaining α's. Bless brentq for its power to find roots.
from scipy.optimize import brentq
T_draft = 22.09
T_target = 29.92
c = T_draft / T_target
def breakeven_alpha(K):
rhs = K * c + 1
def objective(alpha):
if abs(alpha - 1.0) < 1e-9:
return (K + 1) - rhs
return (1 - alpha**(K+1)) / (1 - alpha) - rhs
if objective(0.9999) < 0:
return 1.0
return brentq(objective, 0.0, 0.9999)
for K in [1, 2, 3, 4, 5, 6, 8, 10]:
print(f"K={K:2d} alpha*={breakeven_alpha(K):.3f}")
After our number-crunching, the rough breakeven acceptance rates for each K is approximately...
K breakeven α
-----------------
1 0.738
2 0.814
3 0.856
4 0.882
5 0.901
6 0.914
8 0.932
10 0.944
So in theory, the more draft tokens we propose (K), the higher we want our draft model's acceptance rate to be in order for speculative decoding to beat just calling the target model directly.
Phase 4, Step 2: Draft, verify, accept (greedy decoding)
Commit: 7373c78
Remember from Inference Engines 0/N: Foundations that our engine uses greedy decoding. That is, instead of sampling from the model's probability distribution, we just take the highest-probability token every time via .argmax().
This turns out to make speculative decoding's acceptance rule pleasantly simple.
For each draft token, we ask: "is this the token the target model would have picked?" In other words, does the draft token match the target model's argmax(target_logits[position])? If yes, we accept and move on to the next position. At the first mismatch, we take the target's token instead and throw away the remaining draft tokens. And if all K tokens are accepted, we get the K+1th token for free from the last target logit, just as we discussed above.
Since we're using greedy decoding, our acceptance rule is deterministic, and so we should expect our output to be byte-for-byte identical to non-speculative decoding.
And this is where we're glad we wrote our snapshot correctness checker from Part 0/N. Speculative decoding is subtle enough that it's very easy to write an implementation that produces plausible-looking output while being silently incorrect.
When you get a chance, please check that our snapshots match with:
modal run modal_run.py::snapshot
Snapshot check — new_tokens=64 K=4
[PASS] acceptance=39.2% prompt='The transformer architecture revolutionized NLP be'
[PASS] acceptance=39.6% prompt='Explain the difference between supervised and unsu'
[PASS] acceptance=37.4% prompt='Once upon a time, a curious fox discovered'
All snapshots match. Spec dec produces identical output to target-only decoding.
Implementation footnote: After some draft tokens are rejected, the draft model's KV cache needs to be rolled back to the last accepted position before the next round of speculation. You can do this with
DynamicCache.crop(seq_len)using HuggingFace's API.If you're failing the correctness check, this might be one of many reasons that it fails.
Phase 4, Step 3: Speculative sampling
Commit: 186dded
As we alluded to in Part 0/N, while greedy decoding simplifies everything with its deterministic-ness, most production inference engines don't work this way. When you're talking to ChatGPT or Claude, the model is usually sampling from the probability distribution at random, not necessarily picking the highest-probability token from said distribution.
Why deterministic acceptance rule no longer works
So how does acceptance work when both the draft and the target are randomly sampling from distributions?
The naive answer, "we accept the draft token if it matches the target's sample," would no longer be sustainable. Since the target's sample is itself random, we'd be rejecting good draft tokens just because the target happened to roll a different number on that pleasant Tuesday evening, and our acceptance rate would be unnecessarily low for no good reason.
Our acceptance rule, nondeterministic
Instead of looking for a perfect target-draft match, we accept draft token d at position i with probability
min(1, p_target[d] / p_draft[d])
Intuitively, if the target assigns at least as much probability to this draft token as the draft does, accept it unconditionally with probability 1. Otherwise, if the target is less confident in this token than the draft is, accept it proportionally to each model's confidence in the token.
...and our correction sampling rule, also nondeterministic
If we reject our draft token, we sample a correction token from the following residual distribution, renormalized to sum to 1:
max(0, p_target - p_draft)
Concretely, if our target produces the distribution p_target = [0.5, 0.3, 0.2] and our draft produces the distribution, p_draft = [0.7, 0.2, 0.1], we have
p_target = [0.5, 0.3, 0.2]
p_draft = [0.7, 0.2, 0.1]
-------------------------------------
p_target - p_draft = [-0.2, 0.1, 0.1]
max(0, ...) = [0.0, 0.1, 0.1]
renormalized = [0.0, 0.5, 0.5]
and we sample from this renormalized distribution [0.0, 0.5, 0.5] to get our correction token.
Why bother with this math if it's all random anyway?
If our tokens are randomly sampled anyway, why does it matter what distributions we sample our tokens from?
The gist is that we want to preserve our target model's distribution. That is, given a particular input for two models, Target Model Without Specdec and Target Model With Specdec, we want the probability that any given sequence of tokens gets generated to be exactly the same.
Since we care about preserving the target distribution, we can't just sample from
p_targetdirectly, as that would over-represent tokens that the draft model and target model are mutually confident about.According to the great minds behind Leviathan et al. (see A.1 Correctness of Speculative Sampling for proof) and Chen et al., who independently introduced speculative decoding, we can prove that when we use the speculative sampling scheme, the output distribution of speculative decoding is exactly the same as the target model's distribution. The formal proof is in Leviathan et al.'s appendix if you'd like to verify it yourself.
Now, since our output is non-deterministic, our Phase 0 snapshot checker no longer applies. A mismatch isn't terribly informative, since we already know that two correct runs can produce different outputs.
So, we need a new correctness signal, and in its place, we introduce an acceptance rate metric in harness/bench.py. In this metric, we track what fraction of draft tokens the target accepts on average across a run.
Although our acceptance rate monitor won't tell us if our distribution is correct the same way a mathematical proof would, it serves as a useful sanity check, such that if our acceptance rate drops alarmingly low, we would know that something is wrong with our rejection sampling implementation.
Run it Yourself
To see speculative sampling in action, we'll run two demos that show how acceptance rate varies depending on what we're asking the model to generate.
The first demo runs speculative decoding at temperature 1.0 across two sets of prompts, "easy" factual questions and "hard" creative prompts, to illustrate that acceptance rate is heavily affected by the type of task.
modal run modal_run.py::acceptance_demo
model=Qwen/Qwen3-4B draft=Qwen/Qwen3-0.6B K=4 T=1.0 new_tokens=128
EASY PROMPTS
prompt accept tok/s
------------------------------------------------------------------
What is the capital of France? 66.7% 25.7
Is Python interpreted or compiled? Answer i... 30.2% 17.7
What is 2 + 2? 53.4% 26.6
Name the three primary colors. 37.0% 19.9
AVERAGE 46.8% 22.5
HARD PROMPTS
prompt accept tok/s
------------------------------------------------------------------
Write a short story about a robot who learn... 22.8% 15.8
Describe the history of the Roman Empire in... 27.4% 17.6
Compose a poem about the feeling of autumn ... 22.1% 16.0
Explain the philosophical implications of t... 25.9% 17.2
AVERAGE 24.5% 16.7
Notice the gap between easy and hard prompts! Factual questions have more predictable answers, so the small draft model and large target model tend to agree more often. Creative writing has a much larger space of plausible continuations, so the draft model's guesses get accepted much less frequently.
Meanwhile, our second demo fixes a single prompt and sweeps temperature from 0.0 to 1.5. If you're new to the concept of temperature, temperature controls how concentrated or spread out the model's probability distribution is. At temperature 0.0, the distribution collapses to a spike on the single most likely token (essentially equivalent to greedy decoding). At higher temperatures, the probability mass is more spread out across more tokens, making the model more creative but also less predictable.
modal run modal_run.py::temperature_demo
model=Qwen/Qwen3-4B draft=Qwen/Qwen3-0.6B K=4
prompt: 'Explain how neural networks learn from data.'
temperature acceptance
--------------------------
0.0 33.6% ██████
0.3 36.6% ███████
0.7 38.0% ███████
1.0 30.5% ██████
1.5 25.4% █████
As temperature rises, the draft and target distributions both spread out, but they spread out in different ways, and thus are more likely to disagree. So acceptance rate falls as temperature rises, and with it, the speedup from speculative decoding erodes.
So typically we want to find a sweet spot for temperature, enough for varied, interesting outputs, but not so much that the draft model can no longer keep up with the target model.
Phase 4, Step 4: The sweep for the right K
Commit: cac6bcf
We have one last question to answer before we can wrap up Phase 4: what's the right K for our particular pairing of draft model?
Can you predict the answer?
Before we run the sweep, we actually have everything we need to make a pretty good guess.
Go back to our breakeven table (feel free to scroll up, I'll still be here). Even at K=1, the most forgiving setting, our draft model needs an acceptance rate of at least 73.8% to beat baseline.
Now look at our acceptance demo results. Our best acceptance rate, "What is the capital of France?" at temperature 1.0, was 66.7%! That's already below the most forgiving breakeven rate.
So, do you expect speculative decoding with our draft model Qwen3-0.6B to help much?
Now let's run the sweep across K:
modal run modal_run.py::sweep
model=Qwen/Qwen3-4B draft=Qwen/Qwen3-0.6B T=1.0 new_tokens=128
K easy tok/s easy ms/tok easy accept hard tok/s hard ms/tok hard accept
--------------------------------------------------------------------------------
0 (baseline) 42.1 23.74 — 42.7 23.41 —
1 28.8 34.76 42.9% 30.2 33.15 36.8%
2 24.6 40.66 34.7% 24.8 40.39 29.2%
4 21.9 45.75 34.2% 19.4 51.47 23.9%
8 15.0 66.85 20.7% 13.2 75.89 15.6%
16 10.8 92.88 14.4% 7.9 125.87 8.8%
Best K for easy text: K=1 (0.68× vs baseline)
Best K for hard text: K=1 (0.72× vs baseline)
As we expected, or, hopefully, as you expected, our draft model doesn't agree with the target often enough to overcome the overhead of running two models. And it's individually not that much faster than our target, hence why we can't do better than 1.32x speedup even if it perfectly agreed with the target.
In practice, selecting the right draft model is a matter of trial and error. The purpose of this post was to give you a mental model to run that trial in a slightly more principled way: (1) benchmark both models, (2) compute your breakeven acceptance rates, and (3) measure your actual acceptance rates, so you know whether a particular draft model is worth your time before you try it.
That said, we're not that fussed about Qwen3-4B specifically; the real fun starts in the next post. Our endgame is to run this same search for a much larger target model, and for that we'll take the time to find a draft model that genuinely earns its keep.
Ode to Principled Laziness
I'm absolutely delighted by the laziness behind speculative decoding. The insight that you can use a smaller, faster model as a ghostwriter, is quite elegant, and non-obvious yet obvious in the retrospect.
And, behind this laziness, I'm impressed by the amount of effort put into making sure said laziness is correct, in the mathematical proofs that guarantee the output looks statistically identical to our larger, more expensive model, no matter how haphazardly rushed the ghostwriter is.
We've only scratched the surface here, and if today's post piqued your curiosity, there's a much, much deeper rabbit hole to fall into.
I'll let you in a little on one such rabbit hole for our next post. As a teaser, our new target model will be the Qwen3-35B-A3B, a Mixture of Experts model, a very different beast from the Qwen3-4B (to think we once described the humble Qwen3-4B as beefy back in Inference Engines 1/N: KV Cache!). We'll introduce what MoE is and why it makes finding a compatible draft model a much hairier problem than it was for our Qwen3-4B.
In our quest to find the Qwen3-35B-A22B its perfect ghostwriter, we'll run a little reality TV show of sorts. Four candidates will audition for the coveted role of "draft model for the magnanimous Qwen3-35B-A22B," and we'll measure who earns the target's trust.
Until next time!

MoE Specdec Follow-Up
I suppose I should summarize what I did and found, since I'm opting not to write a separate post about MoE specdec.
In short, the model was shipped with multi-token prediction (MTP) available, and I found that simply enabling MTP and asking it to predict the next K tokens for the highest available setting for K performed better than bringing in some foreign draft model.

MTP is this knob over here, yes it comes with our Qwen3.5-35B-A22B. (source)
You can think of MTP as "self-speculative decoding". The idea is that instead of training your model to predict only the next token, you train it to predict the next N tokens simultaneously, using N independent output heads on top of a shared model trunk.
A Little More Into MTP
A transformer model produces its output through "heads", which are projection layers that each map the model's internal hidden state to a prediction over the vocabulary. During training, each head looks at the same hidden representation and tries to guess a different step into the future; head 1 predicts token t+1, head 2 predicts t+2, and so on.
We normally just use head 1 for inference, but we can toggle on the switch for MTP, thereby using the other heads as well.
In this way, we can ask our target model's attention heads to propose tokens 2 through n speculatively, verify them in parallel with its main model, and get our K+1 tokens for the price of one forward pass, no separate draft model needed!
I had looked into finetuning an EAGLE-3 (paper here), a diffusion model Dflash (paper here), and sweeping the smaller models from the Qwen family.

I suspect that with enough tuning, any of EAGLE-3 or Dflash would match or outperform the target model with MTP enabled. Given that MTP works out of the box, it made sense to use it as the baseline and move on. Finetuning a custom draft model is still on the list, but it's behind other work that's higher priority at the moment.
